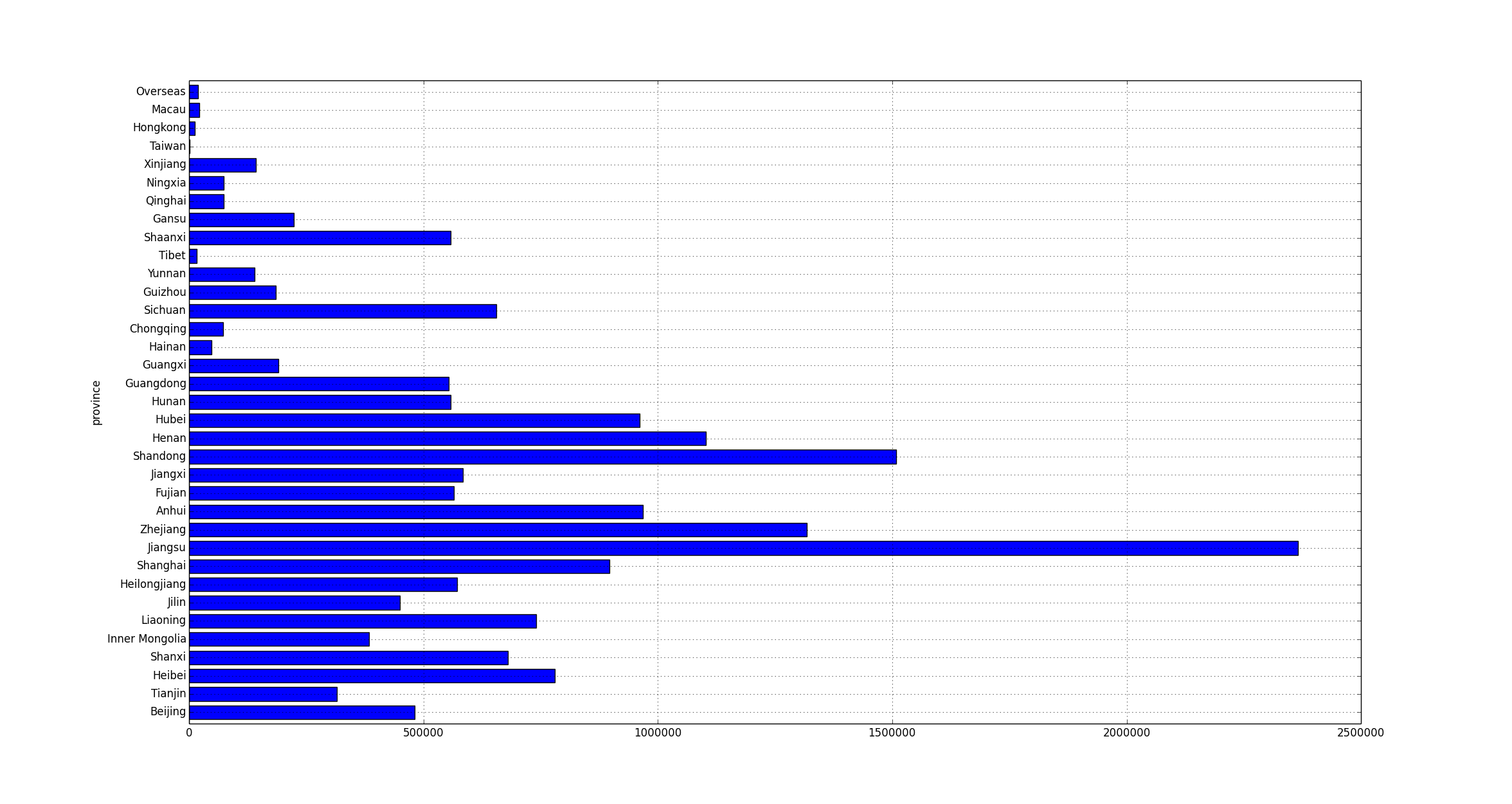
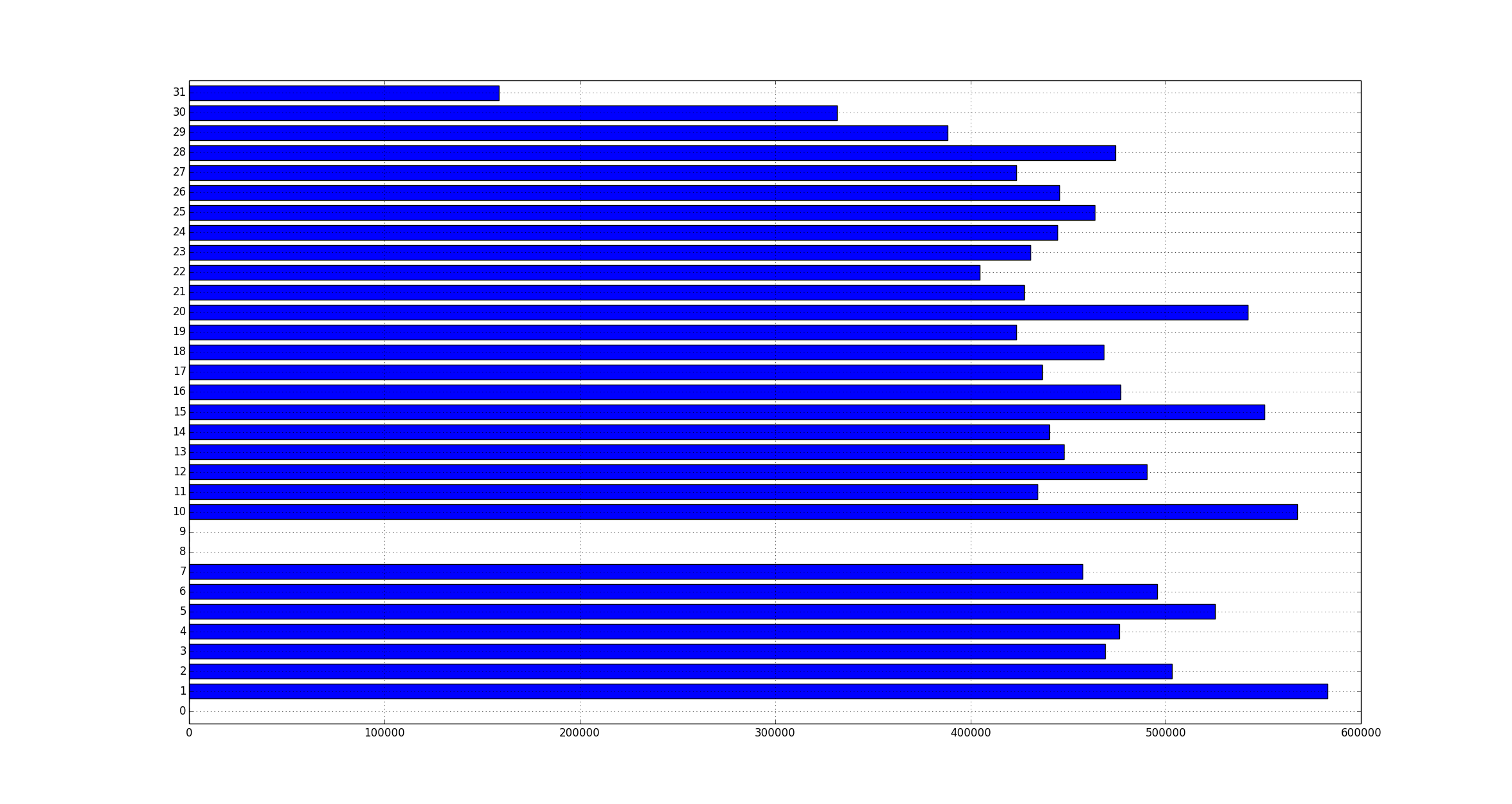
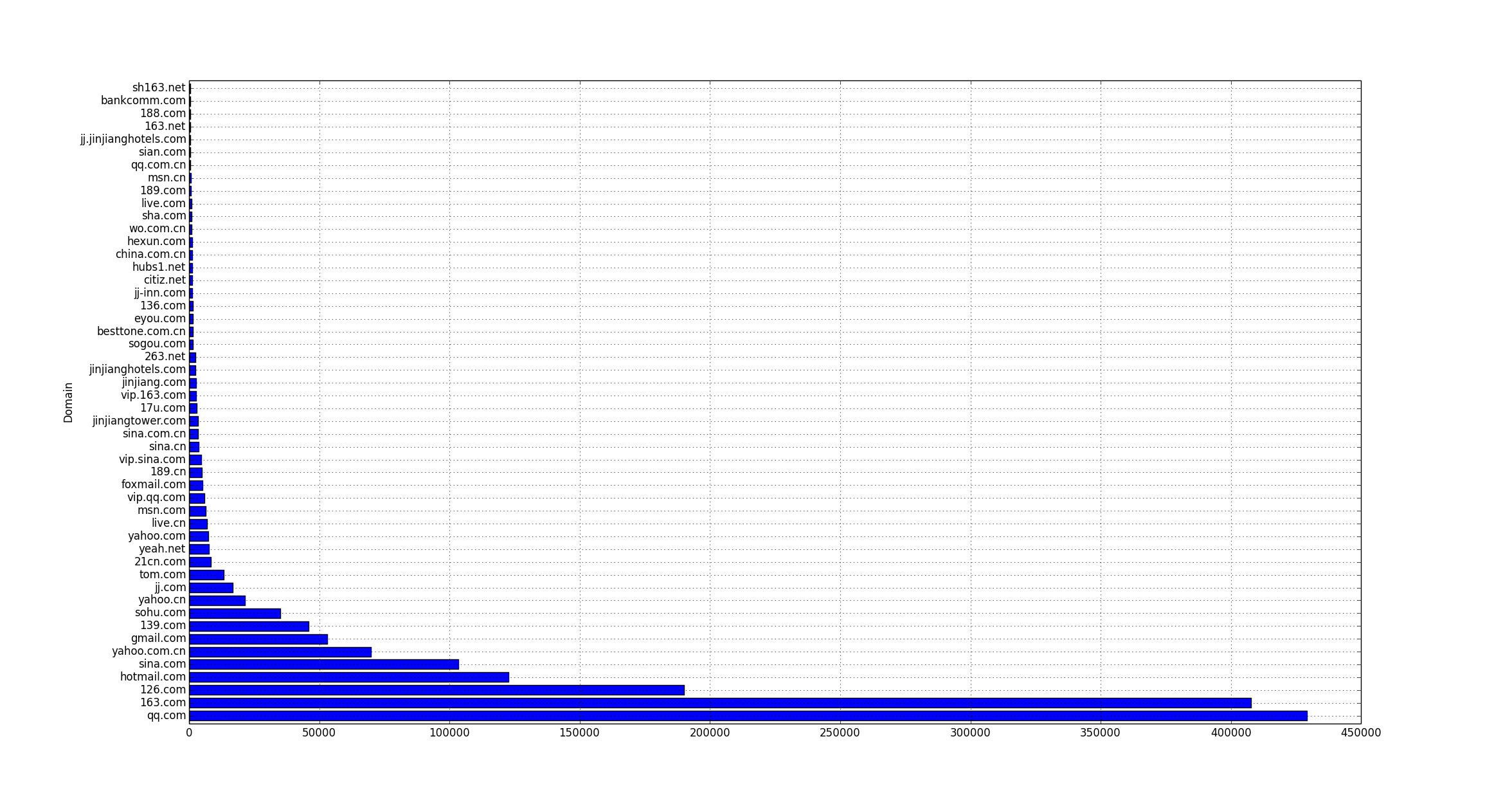
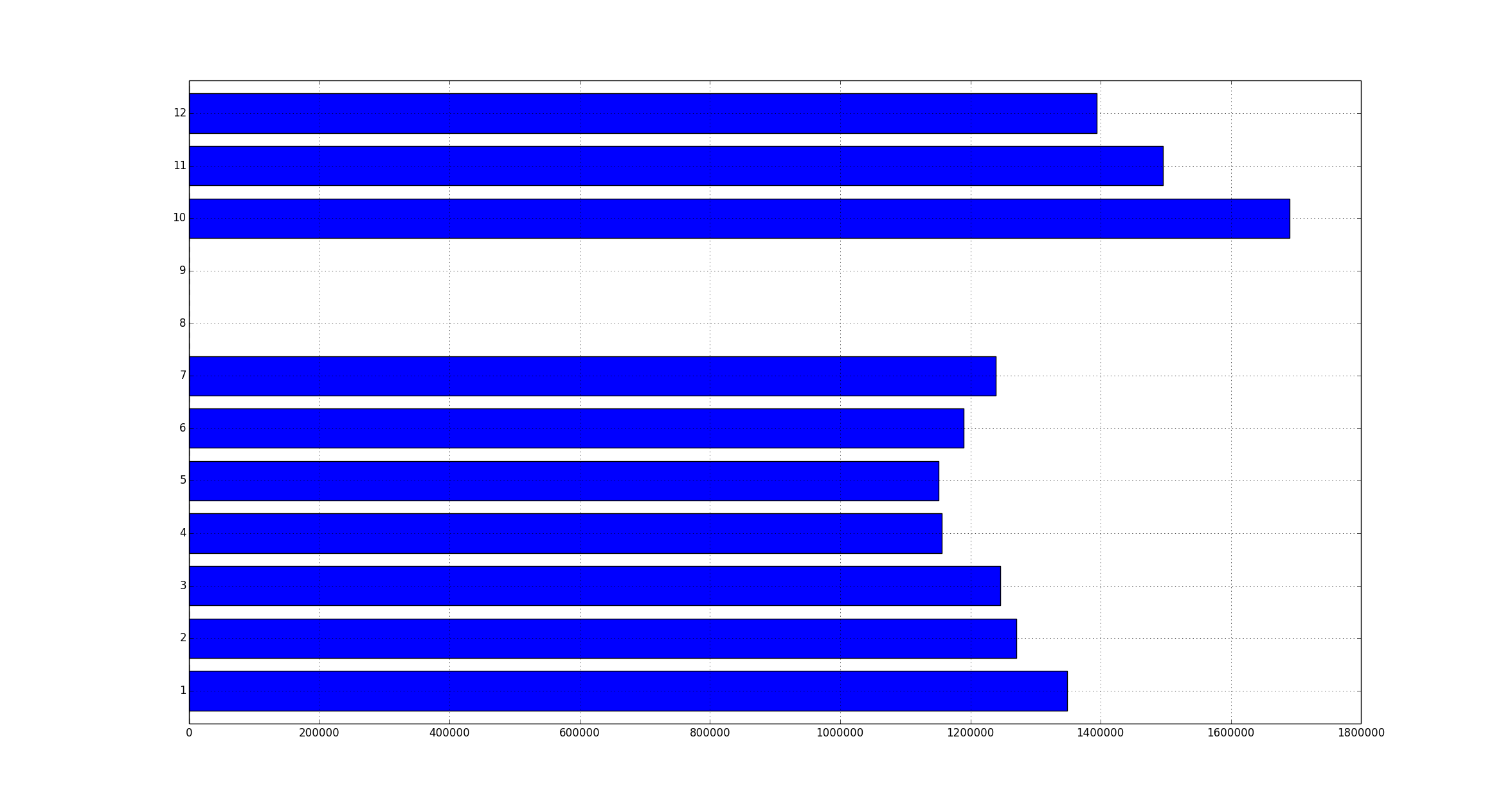
In my project I need to run some local tests with data from a production elasticsearch cluster, so I exported data from the production server and imported to my local cluster. This can also be used when backing up and restoring data. Here’re the instructions.
Before you start, check out the official documentation: Snapshot and Restore.
Backing up/exporting data:
- Modify your eleasticsearch configuration file (normally elasticsearch.yml) and add a path.repo line, for example:
path.repo: /usr/local/var/backups/
- Make sure this path has the correct permissions so that elasticsearch can read and write.
- Create snapshot:
curl -XPUT http://localhost:9200/_snapshot/my_backup -d '{"type": "fs", "settings": {"compress": "true", "location": "/usr/local/var/backups/"}}}' curl -XPUT http://localhost:9200/_snapshot/my_backup/snapshot_1?wait_forcompletion=true - Copy the files in the configured location to your local machine.
Restoring/importing data:
- Modify your local elasticsearch configuration similarly like step 1 when backing up.
- Place the snapshot files to the repo path.
- Close your indices:
curl -XPOST http://localhost:9200/knx-bus/_close
- Import data:
curl -XPOST http://localhost:9200/_snapshot/my_backup/snapshot_1/_restore?pretty
- Reopen your indices:
curl -XPOST http://localhost:9200/knx-bus/_open
It is important that your the elasticsearch version on your importing party is compatible with the one exporting data, i.e., in this case your local machine has to be the same version or newer. If not, you need to upgrade elasticsearch first. The official documentation says:
2 CommentsThe information stored in a snapshot is not tied to a particular cluster or a cluster name. Therefore it’s possible to restore a snapshot made from one cluster into another cluster. All that is required is registering the repository containing the snapshot in the new cluster and starting the restore process. The new cluster doesn’t have to have the same size or topology. However, the version of the new cluster should be the same or newer than the cluster that was used to create the snapshot.